

前言
上次簡單介紹了 人工智慧、機器學習以及深度學習 之間的差別,也探討了人工智慧如何套用在資訊安全。在資安領域裡,存在著許多威脅。像是社交郵件、變臉詐騙或是DDoS攻擊等,都可能造成企業或個人的財產損失。因此如何預防及偵測,便是十分重要的工作。隨著人工智慧的出現,偵測這些惡意攻擊的技術也有一大進步。這次則要介紹AI中,機器學習以及深度學習詳細的運作方式,以及在資安領域中應用的案例。
機器學習
在上一篇文章中,我們提到機器學習是透過大量資料來訓練機器,並告訴機器該透過什麼樣的特徵來判斷事物。而訓練實際上到底是做了什麼事情,才能讓機器學會判斷呢?
「訓練」其實就是從大量的函數中,透過訓練資料找出一個最佳的函數。例如說,我們想要訓練機器偵測網路流量是否異常,那麼我們就設定一個 y=w.x+b 的函數。其中的 x是此流量的資訊,像是來源IP、封包大小等;w 和 b 是參數。透過 w.x+b 的運算,計算出異常的機率 y。而訓練便是尋找出最佳的 w 和 b,利用訓練資料進行計算出 y,再透過計算 y 與正確解答之間的誤差來調整 w 和 b 的值,藉此使得這個函數能夠符合流量的資訊以及它對應的狀態。而輸入的 x 便是先前所提到的特徵。
深度學習
而深度學習和機器學習之間最大的差異,便是函數的架構。深度學習使用了「類神經網路」的架構。類神經網路是模擬人類腦中神經的傳遞,來模擬人類思考的方式。類神經網路中存在許多神經元,每個神經元都是前面所說的函數。如下圖所示,數個神經元會組成一層,其中隱藏層數會根據模型架構改變。當層數越多,代表此模型越「深(Deep)」,因此稱為「深度」學習。
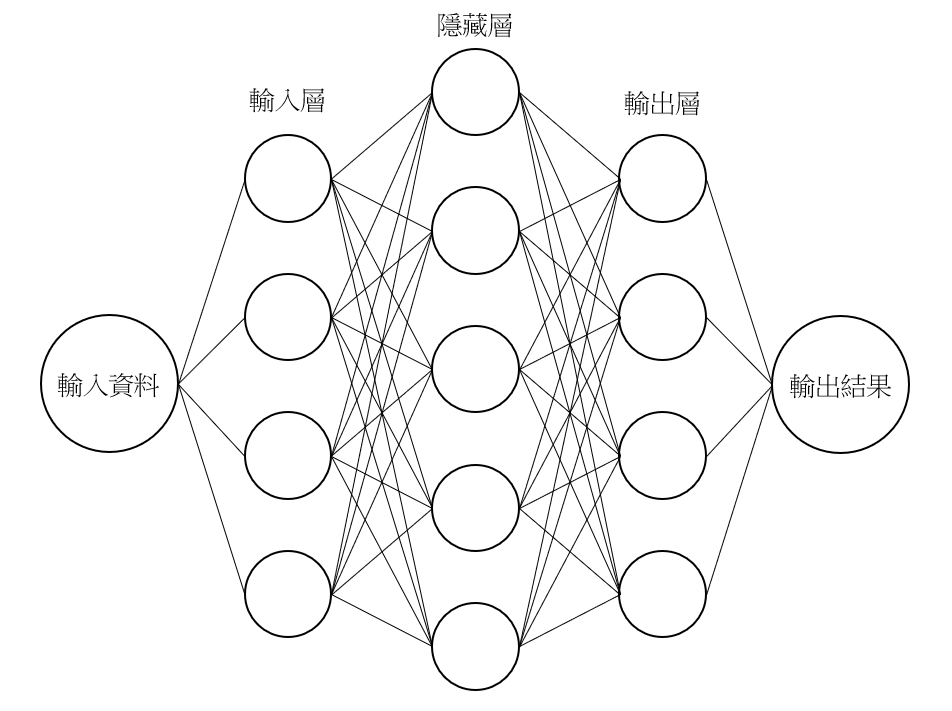
根據大量的資料與解答,每個神經元會學習應該從這些資料裡提取什麼樣的特徵,才能將輸入資料透過一連串複雜的運算轉換成輸出資料。在上一篇文章中提到的「深度學習是讓機器自己學習應該透過何種特徵來判斷事物」,便是藉由這些神經元來做到。
資安防護
在分析網路異常流量、病毒等惡意攻擊,往往需要投入大量的人力。尤其在面對大量複雜的資料時,人工分析的方式是非常困難的。因此讓機器來進行分析與預測,學習怎麼提取特徵、檢測出異常狀況或是惡意攻擊,以降低所需耗費的人力並提高準確度。
根據防護的類型不同,執行機器學習或深度學習的方式也不同。特別是模型的架構以及資料前處理的方式。比如說,判斷是否為變臉詐騙與偵測惡意軟體的方式便不相同。變臉詐騙主要透過分析信件撰寫方式以及內容來進行判斷。因此資料前處理與模型可能著重於文字的提取,以及撰寫風格;而偵測惡意軟體則偏向分析程式的行為模式、權限或環境的要求等等。因此並非透過單一模型便可解決所有的資安威脅,必須根據應用情境來決定模型的架構及資料前處理的方式。
「預測分析」是AI資安應用中最常見的一種,訓練機器能夠從大量複雜的資料中偵測出異常資料。在現今的網路世界中,防禦方總是處於被動的狀態,比起攻擊還要更花心力。面對層出不窮、不斷更新的惡意攻擊,要完全抵擋是非常困難的。因此將AI導入資安的防護工作中,基於更加準確的偵測系統,搭配資安專家的自身經驗,使防禦技術更上一層樓。