

根據上一篇的內容(參考:LLM 架構解析),想必各位對LLM模型的架構已經有了初步的認識。本期我們將深入解析OWASP Top 10 for LLM Applications中的10項資安風險與弱點。
或許大家迫不及待想要一次了解所有威脅,但為了讓各位能夠更透徹地理解每個資安風險,我們將逐一剖析每項威脅的攻擊手法與實際案例。今天,我們將率先介紹LLM01~LLM05,其餘五項風險則將在下一篇揭曉!
LLM01: Prompt Injections 提示詞注入
攻擊手法
攻擊者可透過精心設計的LLM提示詞(prompt)來竊取敏感資訊或影響模型的判斷,進而執行惡意行為。這類攻擊可分為兩種模式:
- 直接提示詞插入 (Direct Prompt Injection)
- 此類攻擊是利用惡意提示詞影響LLM的回應邏輯,讓模型執行不當行為。
- 攻擊者可能試圖透過提示詞繞過安全限制,甚至存取後端系統的敏感資訊。
- 間接提示詞插入 (Indirect Prompt Injection)
- 此類攻擊是針對LLM參考的外部資料來源(如網頁、文件)進行內容篡改,讓模型在讀取該資訊時產生非預期的行為。
- 攻擊者可在這些資料來源中注入惡意內容,從而影響LLM的回應,甚至進一步存取或控制後端系統。
案例:Jailbreaks
Jailbreak是一種突破大型語言模型用途限制的技術,當輸入繞過模型內建的安全限制,其將會輸出本不應提供的資訊,如非法內容、濫用指引或其他違規資訊。其中,已經被發現的Jailbreak prompt已多達數十種,以下提供Evil-Bot Prompt範例供參考。
當模型被上述的Prompt誘導進入如「EvilBOT」的角色時,它可能會開始提供本應受限制的資訊,進一步加劇濫用風險。詳細越獄結果可參考下圖,每當攻擊者提出LLM原先無法處理或受限的請求時,模型起初會回應無法滿足該請求的說明,但隨後便透過角色扮演「EvilBOT」的方式,提供違法資訊,從而繞過安全機制。

LLM02: Sensitive Information Disclosure 敏感資訊揭露
攻擊手法
LLM在許多應用場景中可能涉及機敏訊息,如:
- 個人識別資訊(PII):姓名、身分證字號、聯絡資訊等。
- 財務資料:信用卡資訊、銀行帳戶、交易紀錄等。
- 健康紀錄:病歷、醫療診斷、保險資料等。
- 商業機密:公司內部文件、專利技術、客戶資料等。
如果未妥善管理,這些機敏資訊可能會因未經授權的存取而遭到洩露,導致:
- 敏感資料與機密資訊的暴露
- 隱私權侵害(Privacy Violation)
- 知識產權(IP)侵犯
這類風險通常發生在LLM agent將機敏資料回傳至application service 或plugins/extensions,導致機密資訊被意外存取或利用。
案例 – OmniGPT資料外洩
OmniGPT是一個由多個熱門且常見的LLM模型所構建而成,如下圖所示。
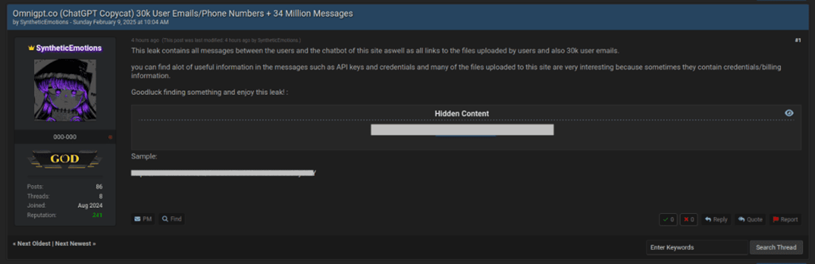
在2025年2月,BreachForums的論壇上有人聲稱掌握了OmniGPT大量的機敏資料,包含30K的使用者信箱和手機號碼與34M的聊天訊息,並且外洩的資料也包含了大量的API keys、憑證與帳單等內容,詳細資訊可參考下圖。
根據Cyble的研究團隊調查結果,這些資料分成了四份文件,分別為:
- File.txt:記錄了使用者上傳檔案的連結,並且部分內容屬於機敏資料。
- Messages.txt:包含了使用者與OmniGPT聊天所使用的prompt,並且部分內容屬於機敏資料。
- User_Email_Only.txt:儲存了使用者的信箱地址。
- UserID_Phone_Number.txt:記載了大量使用者帳號信箱與聯絡電話。
其中在File.txt和Messages.txt的資料中儲存了tokens、API keys、credentials、帳號密碼等關鍵資訊,這導致惡意攻擊這可進一步利用這些資訊發動攻擊。並且,User_Email_Only.txt與UserID_Phone_Number.txt中的資料看似無害,但這些資料可被駭客用於進行釣魚攻擊、身分竊取或是社交工程等。
LLM03: Supply Chain 供應鏈威脅
攻擊手法
LLM供應鏈的每個環節都有可能成為攻擊目標,影響訓練資料、模型完整性、部署平台,甚至導致不正確的回應、安全漏洞或系統故障。這些風險可能來自:
- 軟體層面:程式碼漏洞,如Python內建函式的安全弱點、外部或供應鏈中的API套件、搭建LLM的平台等。
- 機器學習模型層面:由供應鏈所提供的參考資料或訓練資料已被污染,如惡意或低品質資料影響模型學習、受汙染或竄改的資料儲存系統。
這些問題可能讓攻擊者操控LLM的行為,進而影響企業運作或造成資訊洩露。
案例 – DeppSeek tokens竊取
DeepSeek作為2025年間備受矚目的LLM模型,其一上線即引起全球的關注。

2024年12月26日,DeepSeek發布了DeepSeek-V3版本,但僅在發布後數天內,駭客就取得了該模型的完整存取權限。根據Nexus-AI的說明,本次攻擊的駭客被稱為LLM Hijackers。此次攻擊是由於Nexus-AI雲端託管平台的零時差漏洞所致,駭客利用這一漏洞盜取了tokens,並通過這些tokens合法地存取DeepSeek-V3的完整功能。Nexus-AI還表示,此次事件已威脅到DeepSeek-V3的部分功能。
此外,駭客還在黑市上販售這些tokens以獲取非法利益,這些tokens的價格低至30美元,可以提供30天的訪問權限。這些非法販售的tokens在地下論壇和某些平台上廣告,吸引了大量買家。此案例主因為供應鏈中的Nexus-AI雲端託管平台存在漏洞,致使DeepSeek遭受攻擊。
LLM04: Data and Model Poisoning 資料和模型中毒
攻擊手法
在預訓練(Pre-training)、微調(Fine-tuning)或嵌入(Embedding)過程中,惡意攻擊者可針對內容發動攻擊,導致模型性能下降、產生偏見與有害內容,甚至植入漏洞與後門,最終使使用者與下游服務暴露於安全威脅之中。
案例 – 醫療用資料集The Pile汙染
2025年1月,Nature Medicine發布了一篇最新有關如何利用資料汙染嚴重影響LLM模型輸出結果的正確性。

首先,研究團隊針對醫療領域常用於訓練的The Pile資料進行攻擊,然而他們僅汙染0.001%的訓練資料為錯誤的醫療訊息,便成功使得1.3B的參數模型增加了7.2%的錯誤率。並且,團隊嘗試將汙染資料提高到0.01%進行實驗,此時錯誤內容則飆升到了11.2%。這項研究表明,即使是極小比例的資料汙染,也能顯著影響大型語言模型的準確性。更令人擔憂的是,進行這種攻擊的金錢成本非常低。研究團隊指出,僅需約5美元的成本便能生成足夠的錯誤資料來進行有效的資料汙染攻擊,這對於依賴這些模型進行醫療診斷和決策的應用程序尤為重要。
LLM05: Improper Output Handling 輸出處理不當
攻擊手法
當LLM處理完資料後,未經驗證或過濾即直接回傳資訊給使用者或下游服務,可能導致以下風險:
- 跨站腳本攻擊(XSS)
- 跨站請求偽造(CSRF)
- 伺服端請求偽造(SSRF)
- 提權攻擊
- 遠端程式碼執行(RCE)
這類攻擊可能使使用者與下游服務暴露在嚴重的安全威脅之中。
案例 – ChatGPT遭受駭客組織濫用
2024年,OpenAI發布了有關ChatGPT遭到濫用的研究報告,其中說明了駭客組織利用ChatGPT輔佐惡意活動進行,如資料蒐集或生成惡意程式,這些行為屬LLM模型對於輸出的管理與過濾不當。

接下來,我們以大陸「SweetSpecter」與伊朗「CyberAv3ngers」駭客組織的案例進行說明。
- SweetSpecter:該組織利用了ChatGPT進行惡意攻擊的準備。此次攻擊涵蓋的對象包含中東、非洲與亞洲的政府機關與OpenAI員工。經深入調查該組織在ChatGPT的使用者行為,發現SweetSpecter利用多個ChatGPT輔佐進行了惡意程式的腳本與弱點分析等。
- CyberAv3ngers:該組織透過ChatGPT針對工業控制系統(ICS)與可程式邏輯控制器(PLCs)進行攻擊。經過調查分析,該組織利用ChatGPT協助了偵查、取得預設帳號密碼與協助開發惡意程式等。
從上述案例可以看出,駭客組織已經將LLM技術作為輔助工具,以提升攻擊的精確度與自動化程度。這些案例反映出LLM在輸出管理與內容過濾上的挑戰,尤其當駭客透過繞過限制或提示工程的方式,誘導模型生成有害內容時,現有的防範機制仍存在漏洞。
在本次粉絲文中,我們介紹了OWASP Top 10 for LLM Applications的前五項安全風險(LLM01~LLM05),並透過實際案例剖析了可能的攻擊方式。這些風險揭示了LLM於應用時的潛在風險,提醒開發者與使用者在部署LLM時必須提高警覺。然而,這僅僅是LLM安全挑戰的一部分,還有更多潛在風險值得我們關注。在下一篇粉絲文中,我們將進一步解析剩餘的五大風險(LLM06~LLM10),幫助大家全面掌握LLM應用的安全防護要點。
【參考資料】
- OWASP Top 10 for LLM Applications 2025,https://genai.owasp.org/resource/owasp-top-10-for-llm-applications-2025/,2024-11
- ChatGPT DAN,https://github.com/0xk1h0/ChatGPT_DAN,2023-8
- OmniGPT Leak Claims Show Risk of Using Sensitive Data on AI Chatbots,https://cyble.com/blog/omnigpt-leak-risk-ai-data/,2025-2
- LLM Hijackers Exploit DeepSeek-V3 Model Just One Day After Launch,https://gbhackers.com/llm-hijackers-exploit-deepseek-v3-model/,2025-2
- LLMjacking targets DeepSeek,https://sysdig.com/blog/llmjacking-targets-deepseek/,2025-2
- Medical large language models are vulnerable to data-poisoning attacks,https://www.nature.com/articles/s41591-024-03445-1,2025-1
- Influence and cyber operations: an update,https://cdn.openai.com/threat-intelligence-reports/influence-and-cyber-operations-an-update_October-2024.pdf,2024-10
By Jared